Notte: The Web Browser for LLM Agents
Notte is about building the agentic internet. That is accessibility tools to make browser management, web navigation and webpage ingestion tailored to LLMs needs. This takes the form of a simple API that transforms any webpage into structured text, reflecting what data is available on the page (scraping) and what actions can we perform.
Community Showcase: Developer's First Experience
Something cool happened while writing this memo. A software engineer and YouTuber who builds AI agents for crypto organically found our project on GitHub and got excited about it. He made a 3mins demo video on his own and asked us yesterday (Jan 20) if he could share it with his YouTube and Twitter audience (we said yes ofc). Since it shows both what we're building and how developers are organically discovering our tool, I thought it'd be a great way to introduce the project to the community.
Building agents with notte
This is a video that is already 1 week old showcasing Browser Use (Claiming to be the best) vs. a very simplified agent system built on TOP of Notte. The code of this agent is available publicly and is just 200 lines of code: sample_agent.py
🚨 Building the entire agent is not our business. We handle the infrastructure. We're just using this example to showcase how with few lines of code, anyone can really plug an LLM to Notte and start building VERY competitive web ai agents.
task = "enter flights details for a Paris to NYC courrier on Jan 18"
—LEFT: BrowserUse
—RIGHT: simple agent build on notte (see how faster)
Notte API
We built an API that given any website, returns a structured textual description in plain english of both the data and available actions a human OR an LLM agent could take from that web page. The API also handle remote web browser session (that is a pain to manage and build yourself).
Example
from notte.sdk.client import NotteClient
cli = NotteClient(api_key="sk-notte-849...")
obs = cli.observe(url="https://www.google.com/travel/flights")The variable `obs` here contains:
- Metadata of the current session, screenshot of the page, etc.
- The available actions on Google Flights structured in text
Something like:
# Flight Search
* I1: Enters departure location (departureLocation: str = "San Francisco")
* I3: Selects departure date (departureDate: date)
* I6: Selects trip type (tripType: str = "round-trip", allowed=["round-trip", "one-way", "multi-city"])
* B3: Search flights options with current filters
# Website Navigation
* B5: Opens Google apps menu
* L28: Navigates to Google homepage
# User Preferences
* B26: Open menu to change language settings🔥 An LLM can now reason on this context and say something like "I want to depart from NYC". On the API hit #2, Notte will process the answer of the LLM and actually EXCUTE the requested action on the cloud hosted browser session. This will then return the next webpage state. That new state will already have NYC inserted in the departure location. And so on until task is done.
Why is this amazing?
Currently this is how things work cf. Browser-Use, LaVague, and all closed source solutions.
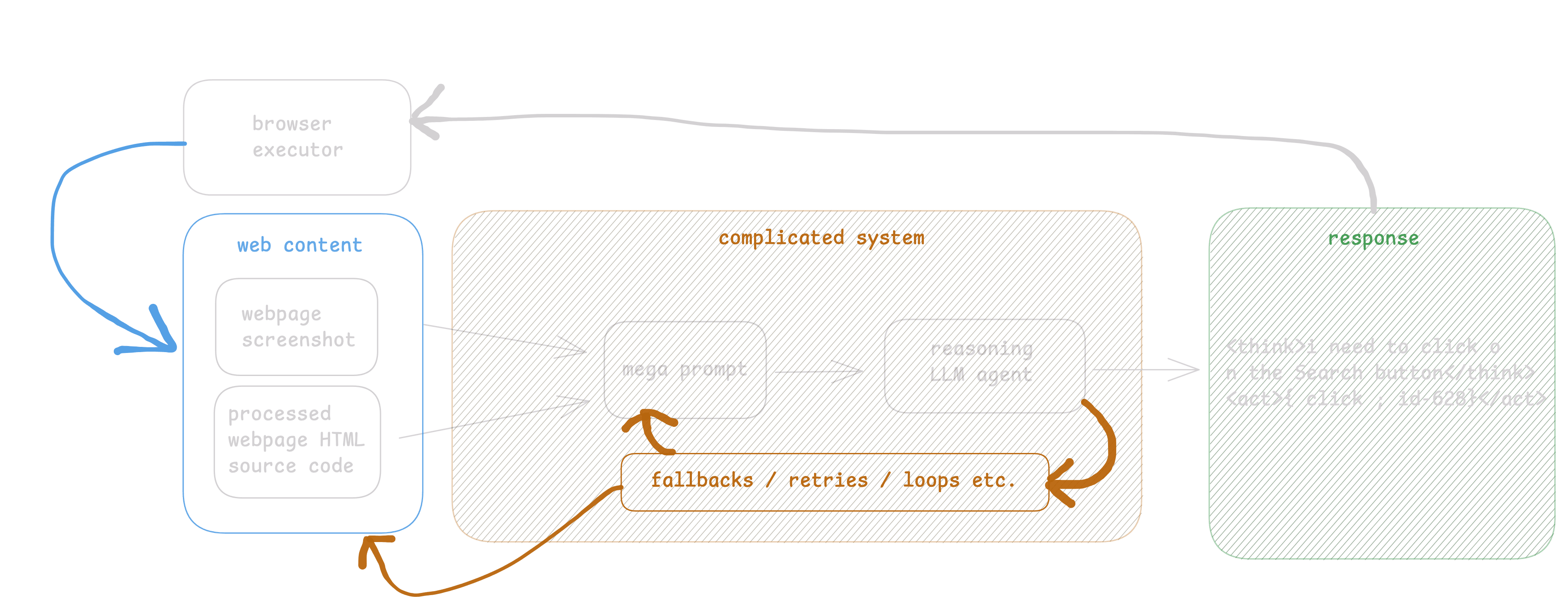
Say a user wants to book a flight from Zurich to NYC and prompts a web agent to do so. The current system open up a browser. Navigate to the best URL they can think of, and then takes 1) a screenshot of the page, and 2) the (somewhat processed) HTML source code of the webpage. These two things are raw dumped to an LLM with a prompt saying something like
Hey ChatGPT this is the huge mess we got from the screenshot and the HTML.
The users wants to book a flight, you are on the Google Flight website.
What should we do next? This is the screenshot: {screenshot} and html: {html}
Here's how to return your answer;
{click, id} if you want to click something
{type, id, text} if you want to type some text somewhere
etc.This is EXTREMELY naive and inefficient as a solution. People started doing this because it worked 80% of the time. And then started building crazy sophisticated downstream systems to address issues that, bottom line, come from the fact the raw input is a bad input signal.
The LLM often fails to parse and digest the information in this way, leading to hallucinations or system crash (eg. clicks id-628 instead of id-627 for search button, or simply hallucinates an id). The other problem is that the HTML and screenshot can blow up to tens of thousands of tokens easily eg. 40-50-60k context easy. This, in turn, is slow and costly to process with Openai.
How notte improves the situation?
→ By working upstream and preparing a structured textual description, the downstream LLM reasoner is able to solve its task much faster and with much more ease. He fails less in the reasoning part as there is no more mess with IDs, and it's faster/cheaper to run the inference as the overall number of tokens was reduced.
🔥 Another very cool side-effect, is that our tech enables to perform "multiple-step" actions in a single shot. Eg. with current system, you would need 3 clicks to log-out from LinkedIn (click your profile, open setting, and click logout). With Notte, we package together "high-level" actions into a single thing the LLM can select eg. "Logout LinkedIn" that would trigger the 3 sub mini actions.
Opensource core tech
The very core of the technology is opensource and readily available on GitHub. This is to increase transparency and endorsement from community, as we believe this is super important in such a noisy space. This community effect also helps to get to a consensus where this devtool is the standard and a commodity for this part of the stack—Browser management and webpage ingestion for AI agents.
While the core of the tech is opensource, it's a real pain to actually boot a server in the cloud and manage your browser sessions etc. A few bold developers might do the stretch, but we expect it to be as with all other opensource tools: People see it looks good, and then just plug to the API. The API has a good free tier, and then once users are locked in, they pay.
Caching and other features
With the API instead of the opensource repo, users also benefit from a bunch of other very cool features.
- Browser management handled for them through Notte API (This is so hard and painful to do, that it has already become a standalone service provided by Browser Base)
- most exciting
- coming up soon
When a new webpage is queried on the API, we process it on the fly for the first time, but then we STORE it in a frequency-based cache. Meaning that if someone else queries the same website no long-after (or at any time if it's a really popular website); chances are high (close to 100%) that we'll already have the response at hand. In that case, the processing time is further reduced from 3-4-5s to <500ms—time of a simple HTTP request.
We are working now on secrets management, VPN, and permissions to allow agents to connect by default to website requiring authentication and/or requiring geolocation. We're also planning to move on to entire Operating System level in a few weeks when browser is stable enough.
Persistent web automations
Misc
Cofounders: Andrea Pinto and Lucas Giordano moved full time mid Oct 2024. We spent a month or so incubating and thinking very deeply on the what, why and hows of our startup. We decided early December 2024 to focus on Notte and started heads down to ship code and product.
important links
- Landing page notte.cc and Console page console.notte.cc
- GitHub open core repo https://github.com/nottelabs/notte
- LinkedIn https://www.linkedin.com/company/nottecc (stealth)
- X/Twitter https://x.com/nottecore (stealth)